Priority Queues¶
The Priority Queue Abstract Data Type¶
Priorities ✏️¶
In this chapter, we introduce a new abstract data type known as a priority queue.
This is a collection of prioritized elements that allows arbitrary element insertion, and allows the removal of the element that has first priority.
When an element is added to a priority queue, the user designates its priority by providing an associated key.
The element with the minimum key will be the next to be removed from the queue (thus, an element with key 1 will be given priority over an element with key 2).
Although it is quite common for priorities to be expressed numerically, any Python object may be used as a key, as long as the object type supports a consistent meaning for the test a < b, for any instances a and b, so as to define a natural order of the keys.
With such generality, applications may develop their own notion of priority for each element.
For example, different financial analysts may assign different ratings (i.e., priorities) to a particular asset, such as a share of stock.
The Priority Queue ADT¶
Formally, we model an element and its priority as a key-value pair. We define the priority queue ADT to support the following methods for a priority queue P:
P.add(k, v): Insert an item with key k and value v into priority queue P.
P.min(): Return a tuple, (k,v), representing the key and value of an item in priority queue P with minimum key (but do not remove the item); an error occurs if the priority queue is empty.
P.remove_min(): Remove an item with minimum key from priority queue P, and return a tuple, (k,v), representing the key and value of the removed item; an error occurs if the priority queue is empty.
P.is_empty(): Return True if priority queue P does not contain any items.
len(P): Return the number of items in priority queue P.
A priority queue may have multiple entries with equivalent keys, in which case methods min and remove_min may report an arbitrary choice of item having minimum key. Values may be any type of object.
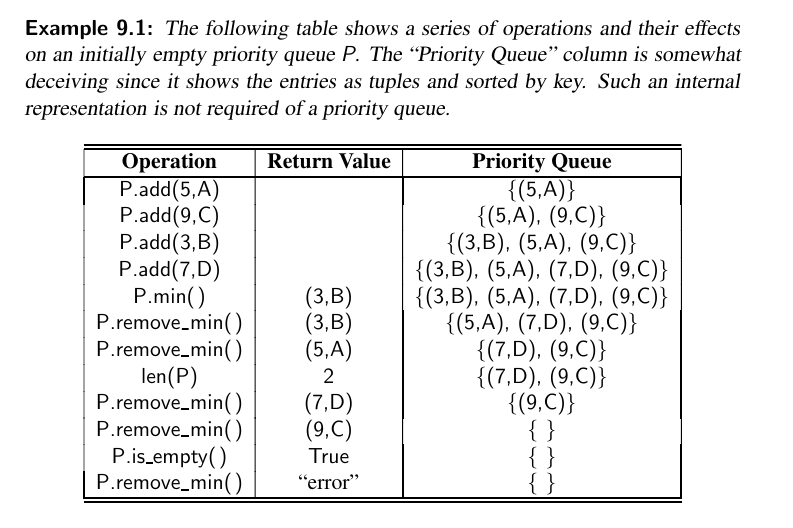
Here is an example:
Extra - Priority Queues in Real World 🥰¶
Python implements priority queues with heaps. A min heap is all you need!
from heapq import heapify, heappop, heappush
a = [4,2,1,6,5,8,2]
# O(n)
heapify(a)
print(a) # [1, 2, 2, 6, 5, 8, 4]
# O(log(n))
print(heappop(a)) # 1
print(a) # [2, 2, 4, 6, 5, 8]
# O(log(n))
print(heappop(a)) # 2
print(a) # [2, 5, 4, 6, 8]
# heaps adjust lists in place
print(a[0] == 2) # True
print(a[1] == 5) # True
print(a[2] == 4) # True
print(a[3] == 6) # True
print(a[4] == 8) # True
Implementing a Priority Queue¶
In this section, we show how to implement a priority queue by storing its entries in a positional list L.
The Composition Design Pattern¶
...
TODO: Not urgent
...
The code:
Implementation with an Unsorted List¶
TODO: Not urgent
...
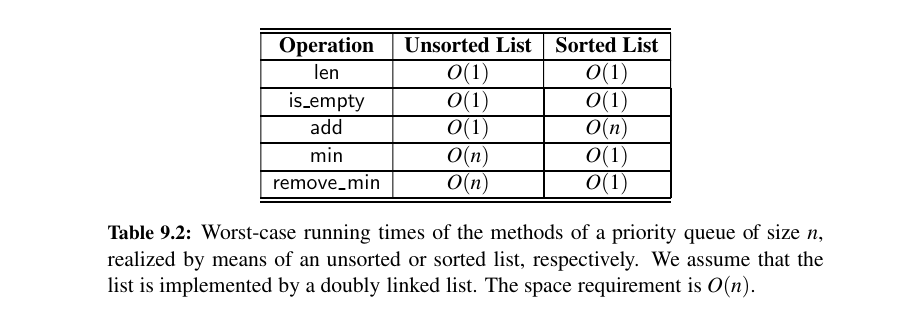
Worst case running times as follows:

The code:
Implementation with a Sorted List¶
TODO: Not urgent
...
Worst case running times - comparison with unsorted:
The Code:
Heaps 💯¶
The two strategies for implementing a priority queue ADT in the previous section demonstrate an interesting trade-off.
When using an unsorted list to store entries, we can perform insertions in \(O(1)\) time, but finding or removing an element with minimum key requires an \(O(n)\)-time loop through the entire collection.

In contrast, if using a sorted list, we can trivially find or remove the minimum element in \(O(1)\) time, but adding a new element to the queue may require \(O(n)\) time to restore the sorted order.
We provide a more efficient realization of a priority queue using a data structure called a binary heap.
This data structure allows us to perform both insertions and removals in logarithmic time, which is a significant improvement over the list-based implementations discussed in Section 9.2.
The fundamental way the heap achieves this improvement is to use the structure of a binary tree to find a compromise between elements being entirely unsorted and perfectly sorted.
If you want to understand heaps just check this wonderful tool.
A min heap has the smallest elements close to the root. 😉
The Heap Data Structure 💖¶
Heap-Order Property: In a heap T , for every position p other than the root, the key stored at p is greater than or equal to the key stored at p’s parent.
Complete Binary Tree Property: A heap T with height h is a complete binary tree if levels \(0, 1, 2, . . . , h − 1\) of T have the maximum number of nodes possible (namely, level \(i\) has \(2i\) nodes, for \(0 ≤ i ≤ h − 1\)) and the remaining nodes at level h reside in the leftmost possible positions at that level.
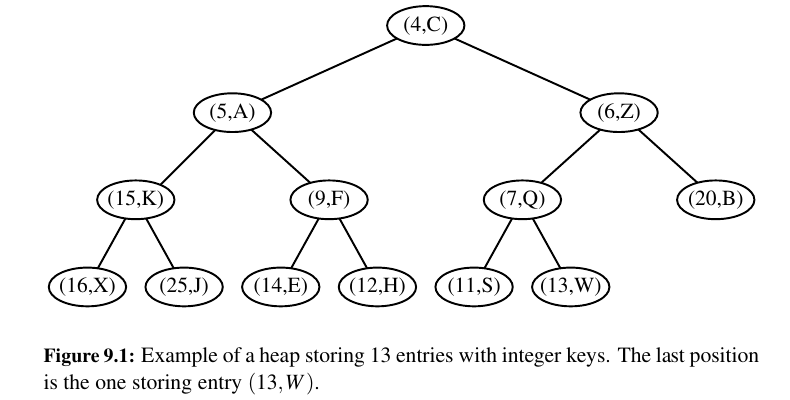
The Height of a Heap
Let h denote the height of T . Insisting that T be complete also has an important consequence, as shown in Proposition 9.2.
Proposition 9.2: A heap T storing n entries has height \(h = ⌊log(n)⌋\) (\(h = ⌊log(n)⌋\) - floor of log n).
Implementing a Priority Queue with a Heap¶
Adding an Item to the Heap¶
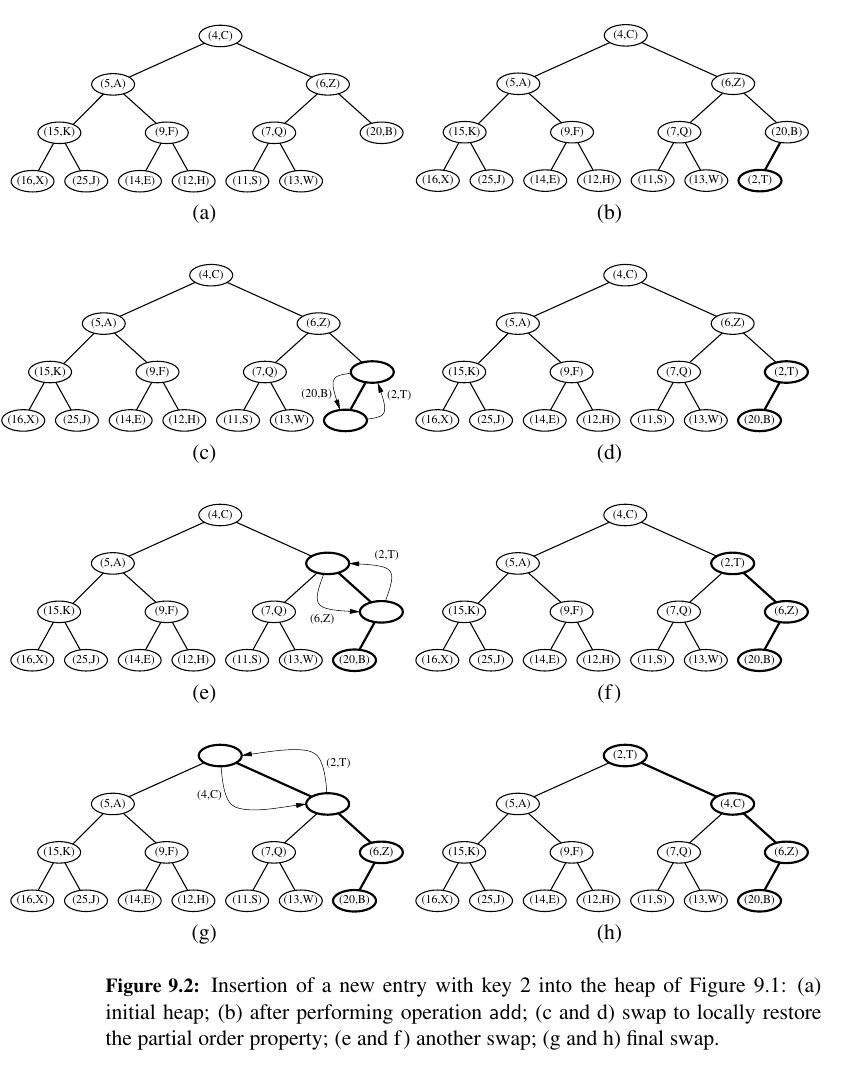
Let us consider how to perform add(k,v) on a priority queue implemented with a heap T.
We store the pair (k, v) as an item at a new node of the tree.
To maintain the complete binary tree property, that new node should be placed at a position p just beyond the rightmost node at the bottom level of the tree, or as the leftmost position of a new level, if the bottom level is already full (or if the heap is empty).
Up-Heap Bubbling After an Insertion¶
After this action, the tree T is complete, but it may violate the heap-order property.
The upward movement of the newly inserted entry by means of swaps is conventionally called up-heap bubbling.
A swap either resolves the violation of the heap-order property or propagates it one level up in the heap. In the worst case, up-heap bubbling causes the new entry to move all the way up to the root of heap T.
Thus, in the worst case, the number of swaps performed in the execution of method add is equal to the height of T . That bound is \(⌊(log(n))⌋\)
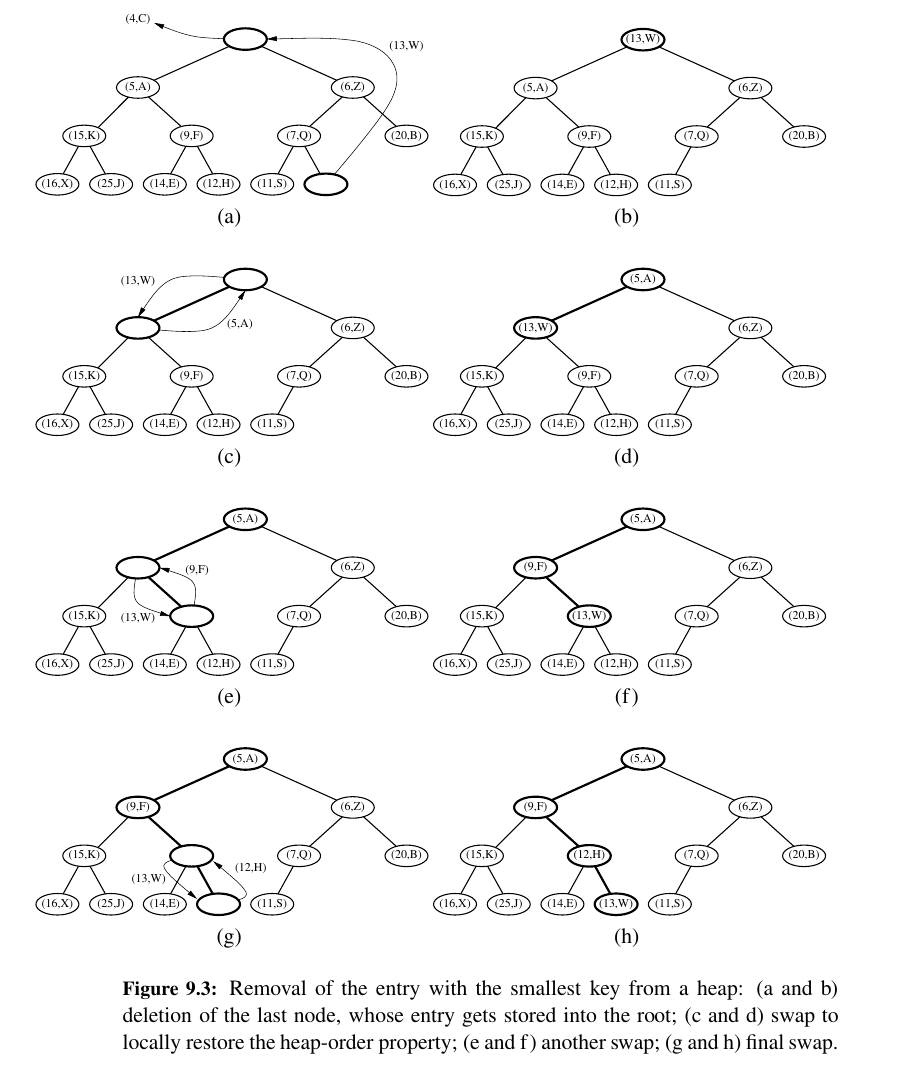
Removing the Item with Minimum Key¶
Let us now turn to method remove_min of the priority queue ADT. We know that an entry with the smallest key is stored at the root r of T (even if there is more than one entry with smallest key).
However, in general we cannot simply delete node r, because this would leave two disconnected subtrees. 🤭
Instead, we ensure that the shape of the heap respects the complete binary tree property by deleting the leaf at the last position p of T, defined as the rightmost position at the bottom most level of the tree.
Down-Heap Bubbling After a Removal¶
We are not yet done, however, for even though T is now complete, it likely violates the heap-order property.
Having restored the heap-order property for node p relative to its children, there may be a violation of this property at c; hence, we may have to continue swapping down T until no violation of the heap-order property occurs (See Figure 9.3.).
This downward swapping process is called down-heap bubbling. A swap either resolves the violation of the heap-order property or propagates it one level down in the heap.
In the worst case, an entry moves all the way down to the bottom level (see Figure 9.3).
Thus, the number of swaps performed in the execution of method remove min is, in the worst case, equal to the height of heap T, that is, it is \(⌊(log(n))⌋\).
Array-Based Representation of a Complete Binary Tree¶
The array-based representation of a binary tree (Section 8.3.2) is especially suitable for a complete binary tree T.
We recall that in this implementation, the elements of T are stored in an array-based list such that the element at position p in T is stored in A with index equal to the level number \(f(p)\) of \(p\), defined as follows:
• If p is the root of T , then \(f (p) = 0\).
• If p is the left child of position q, then \(f (p) = 2 f (q) + 1\).
• If p is the right child of position q, then \(f (p) = 2 f (q) + 2\).
With this implementation, the elements of T have contiguous indices in the range [0, n − 1] and the last position of T is always at index \(n − 1\), where n is the number of positions of T.

Implementing a priority queue using an array-based heap representation allows us to avoid some complexities of a node-based tree structure.
In particular, the add and remove_min operations of a priority queue both depend on locating the last index of a heap of size n.
With the array-based representation, the last position is at index \(n − 1\) of the array. Locating the last position of a complete binary tree implemented with a linked structure requires more effort. (See Exercise C-9.34.)
If the size of a priority queue is not known in advance, use of an array-based representation does introduce the need to dynamically resize the array on occasion, as is done with a Python list.
The space usage of such an array-based representation of a complete binary tree with n nodes is \(O(n)\), and the time bounds of methods for adding or removing elements become amortized. (See Chapter 5.3.1.)
Python Heap Implementation¶
We use an array-based representation, maintaining a Python list of item composites.
Here is the code:
Analysis of a Heap-Based Priority Queue¶
...
TODO: complete this part.
...
Here are just the results:
| Operation | Running Time | |
|---|---|---|
len(P), P.is_empty() |
\(O(1)\) | |
P.min() |
\(O(1)\) | |
P.add() |
\(O(log(n))\)* | |
P.remove_min() |
\(O(log(n))\)* |
* means amortized, if array based.
Tip
We conclude that the heap data structure is a very efficient realization of the priority queue ADT, independent of whether the heap is implemented with a linked structure or an array.
The heap-based implementation achieves fast running times for both insertion and removal, unlike the implementations that were based on using an unsorted or sorted list.
Bottom-Up Heap Construction¶
...
TODO: Not urgent
...
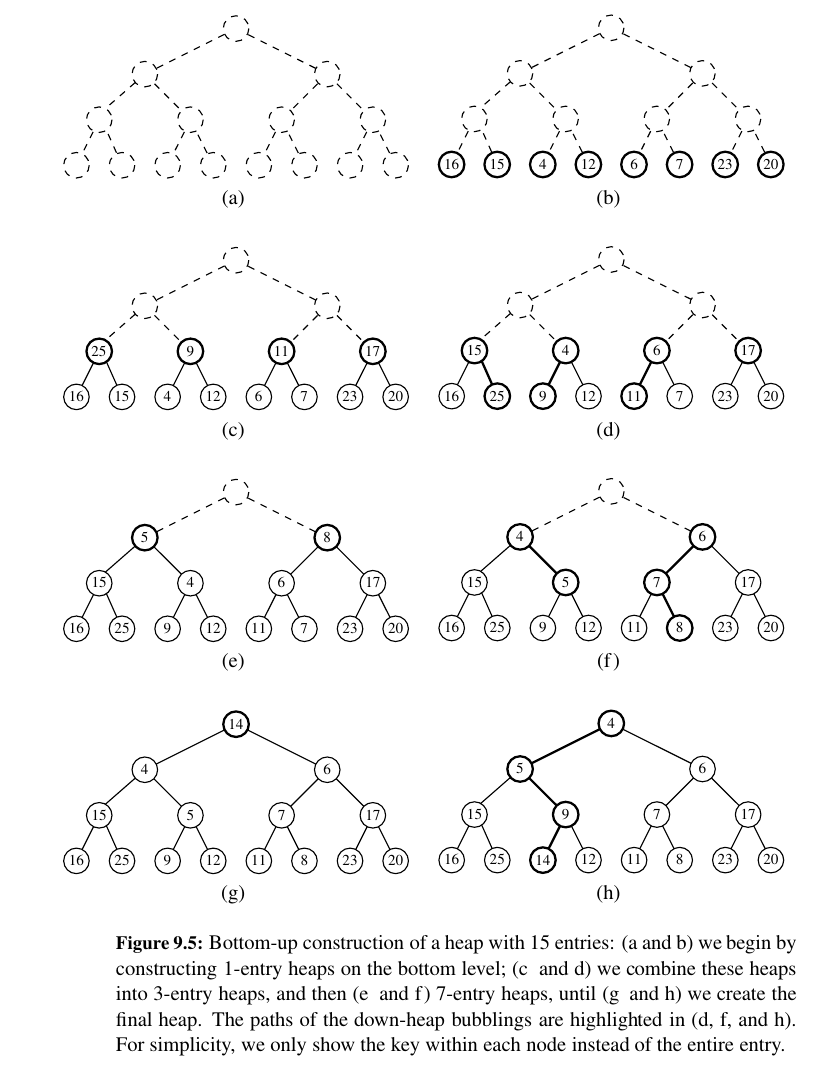
Just know this:
Bottom-up construction of a heap with n entries takes O(n) time, assuming two keys can be compared in O(1) time.
I think heapify works like this ?
Signature: heapify(heap, /)
Docstring: Transform list into a heap, in-place, in O(len(heap)) time.
Type: builtin_function_or_method
Python’s heapq Module 😍¶
This part is important.
Python’s standard distribution includes a heapq module that provides support for heap-based priority queues.
That module does not provide any priority queue class; instead it provides functions that allow a standard Python list to be managed as a heap.
Its model is essentially the same as our own, with n elements stored in list cells \(L[0]\) through \(L[n − 1]\), based on the level-numbering indices with the smallest element at the root in \(L[0]\).
We note that heapq does not separately manage associated values; elements serve as their own key.
The heapq module supports the following functions, all of which presume that existing list L satisfies the heap-order property prior to the call:
| Method | Explained |
|---|---|
heappush(L, e) |
Push element e onto list L and restore the heap-order property. The function executes in \(O(log n)\) time. |
heappop(L) |
Pop and return the element with smallest value from list L, and reestablish the heap-order property. The operation executes in \(O(log n)\) time. |
heappushpop(L, e) |
Push element e on list L and then pop and return the smallest item. The time is \(O(log n)\), but it is slightly more efficient than separate calls to push and pop because the size of the list never changes. If the newly pushed element becomes the smallest, it is immediately returned. Otherwise, the new element takes the place of the popped element at the root and a down-heap is performed. |
heapreplace(L, e) |
Similar to heappushpop, but equivalent to the pop being performed before the push (in other words, the new element cannot be returned as the smallest). Again, the time is \(O(log n)\), but it is more efficient that two separate operations. The module supports additional functions that operate on sequences that do not previously satisfy the heap-order property. |
heapify(L) |
Transform unordered list to satisfy the heap-order property. This executes in \(O(n)\) time by using the bottom-up construction algorithm. |
nlargest(k, iterable) |
Produce a list of the k largest values from a given iterable. This can be implemented to run in \(O(n + k log n)\) time, where we use n to denote the length of the iterable. |
nsmallest(k, iterable) |
Produce a list of the k smallest values from a given iterable. This can be implemented to run in \(O(n + k log n)\) time, using similar technique as nlargest. |
Sorting with a Priority Queue¶
Selection-Sort and Insertion-Sort¶
You can do sorting using priority queues:
Insert all elements to a PQ remove_min 1 by 1.
def pq_sort(C):
n = len(C)
p = PriorityQueue()
# add
for j in range(n):
element = C.delete(C.first())
p.add(element, element)
# remove
for j in range(n):
(k, v) = p.remove_min()
C.add_last(v)
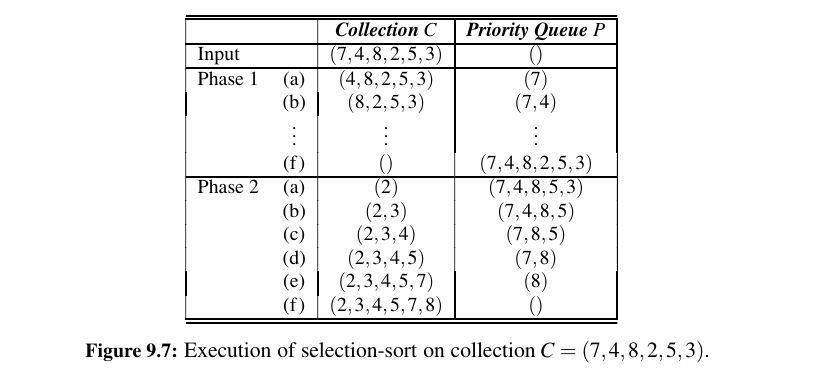
Selection Sort - \(O(n^2)\) Time Complexity¶
TODO: Not urgent
...
If we implement P with an unsorted list, then Phase 1 of pq_sort takes \(O(n)\) time, for we can add each element in \(O(1)\) time. In Phase 2, the running time of each remove_min operation is proportional to the size of P.
Thus, the bottleneck computation is the repeated “selection” of the minimum element in Phase 2. For this reason, this algorithm is better known as ==selection-sort==.
As noted above, the bottleneck is in Phase 2 where we repeatedly remove an entry with smallest key from the priority queue P. The size of P starts at n and incrementally decreases with each remove_min until it becomes 0.
Thus, the first operation takes time \(O(n)\), the second one takes time \(O(n − 1)\), and so on. Therefore, the total time needed for the second phase is \(O(n^2)\).
Here is an implementation for SelectionSort:
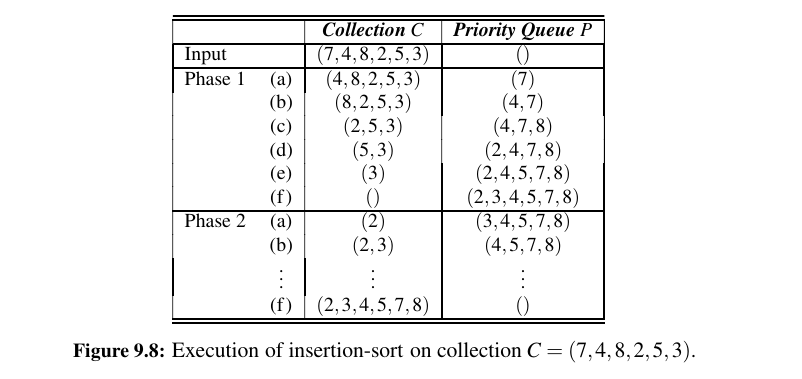
Insertion Sort - \(O(n^2)\) Time Complexity¶
If we implement the priority queue P using a sorted list, then we improve the running time of Phase 2 to \(O(n)\), for each remove_min operation on P now takes \(O(1)\) time.
Unfortunately, Phase 1 becomes the bottleneck for the running time, since, in the worst case, each add operation takes time proportional to the current size of P.
This sorting algorithm is better known as ==insertion-sort== (see Figure 9.8); in fact, our implementation for adding an element to a priority queue is almost identical to a step of insertion-sort as presented in Section 7.5.
The worst-case running time of Phase 1 of insertion-sort is worst-case \(O(n^2)\) time for Phase 1, and thus, the entire insertion-sort algorithm.
However, unlike selection-sort, insertion-sort has a best-case running time of \(O(n)\) (which is kinda irrelevant, but yeah).
Here is an implementation of Insertion Sort:
Heap-Sort - \(O(n*log(n))\) Time Complexity - inplacesorting¶
You can also do sorting using a heap. This is a better sorting than a simple bubble_sort.
Reminder, this was the bubble_sort:
TODO:
...
Here is the most basic implementation of heap sort:
| heap_sort.py | |
|---|---|
This is an example from REAL WORLD:
Adaptable Priority Queues¶
Remove randomly from Queue or add VIP.
We need new methods
- update() - change priority.
- remove() - remove from arbitrary.
Same efficiency -> \(o(log(n))\) for update - remove.
| Operation | Running Time |
|---|---|
len(p), p.is_empty(), p.min() |
\(O(1)\) |
p.add(k, v) |
\(O(logn)^*\) |
p.update(loc, k, v) |
\(O(logn)\) |
p.remove(loc, ) |
\(O(logn)^*\) |
p.remove_min() |
\(O(logn)^*\) |
One smart idea:
def _bubble(self, j):
if j > 0 and self._data[j] < self._data[self._parent(j)]:
self._upheap(j)
else:
self._downheap(j)
...
Locators¶
TODO: Not urgent
...
Implementing an Adaptable Priority Queue¶
TODO: Not urgent
...
Fantastic work! 💛 Let's check out Maps, Hash Tables and Skip Lists now.